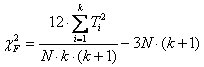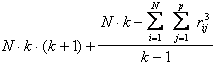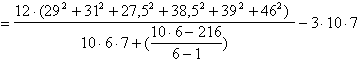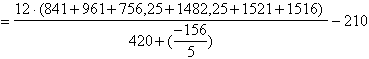|
TEST NON PARAMETRICI PER PIU' CAMPIONI
15.10. test di Friedman O Analisi della varianza per ranghi a 2 criteri di classificazione, con UNA e con k REPLICHE
Il test di Cochran si applica a dati dicotomizzati. Quando è possibile disporre di misure più precise su una scala quantitativa continua, in altri termini quando i valori raccolti sono - almeno di tipo ordinale, - senza o solo con pochi valori identici e - disposti come nell’ANOVA a due criteri o a blocchi randomizzati, per verificare l’ipotesi nulla sulla tendenza centrale H0: me1 = me2 = ... = meK contro l’ipotesi alternativa H1: non tutte le k mediane sono uguali. si ricorre al test proposto da Milton Friedman nel 1937 (con l’articolo The use of ranks to avoid the assumptions of normality implicit in the analysis of variance pubblicato su Journal of the American Statistical Association Vol. 32, pp. 675-701). Come dice il titolo del suo articolo, l’uso dei ranghi da lui proposto permette di evitare le assunzioni di normalità, implicite nell’ANOVA.
E’ l’alternativa non parametrica alll'ANOVA a due criteri di classificazione o a blocchi randomizzati, quando non sono rispettate le condizioni di validità richieste dai test parametrici. E' uno dei test non parametrici più potenti e di uso più generale . Come tale è riportato in quasi tutte le librerie statistiche informatiche, anche quelle che limitano la presentazione di quelli non parametrici a pochi test.
Per una presentazione chiara del problema, è utile che i dati siano riportati in una tabella, nella quale - i valori delle varie righe fanno riferimento agli stessi soggetti e - le colonne ai medesimi casi di studio, come nell’analisi della varianza a due criteri di classificazione di cui è la versione non parametrica. Ma, a differenza dell’ANOVA parametrica a due criteri, - l’ipotesi nulla è una sola e verte sulle k situazioni o casi o trattamenti, - mentre i soggetti o individui sono considerati soltanto come repliche.
NEL CASO DI UN SOLO DATO PER CASELLA, è utile presentare i dati raccolti come nella tabella
Se l’ipotesi da verificare riguarda non il fattore riportato nella colonna ma quello nella riga, è sufficiente scambiare le righe con le colonne. Come risulterà evidente dalla illustrazione della metodologia, la verifica dell’ipotesi sulla tendenza centrale dei due fattori presi in considerazione non possono essere condotte in modo simultaneo, come è fatto nell’analisi della varianza. Quando interessano entrambi i fattori, la verifica dell’uguaglianza delle mediane per ognuno di essi deve essere condotta in tempi successivi, in modo indipendente.
Più sinteticamente, si ricorre al test di Friedman fondamentalmente in 2 situazioni: 1- quando sono state utilizzate misure continue in scale d'intervallo o di rapporto, di conseguenza con nessuna o pochissime misure ripetute, ma non sono rispettate le assunzioni di validità dell'ANOVA; 2- quando sono state usate misure discrete, semi-quantitative o di rango anche se rappresentate in forma simbolica.
Il procedimento è semplice e richiede pochi passaggi.
1 - Data una tabella a doppia entrata
2 - trasformare i punteggi o le misure in ranghi entro la stessa riga, assegnando 1 al punteggio minore e progressivamente valori maggiori fino a k, uguale al numero di colonne, al punteggio maggiore della medesima riga.
3 - Successivamente, sommare per colonna i valori dei ranghi (Ti)
4 - Se l'ipotesi nulla H0 è vera, nelle colonne a confronto i ranghi minori e quelli maggiori dovrebbero essere distribuiti casualmente; pertanto, le somme dei ranghi nelle k colonne (Ti osservati) dovrebbero essere tra loro tutte equivalenti ed essere uguali ad un valore atteso, che dipende solo dal numero di osservazioni,
Ti (attesi) = dove N è il numero di righe. Con i dati dell’esempio, N = 4 e k = 3 Ti (attesi) = la somma di ogni colonna (Ti attesi) dovrebbe essere uguale o almeno prossima a 8, considerando le variazioni casuali.
Se l’ipotesi nulla H0 è falsa , in almeno una colonna si concentrano i ranghi minori o maggiori; di conseguenza, tale somma tende ad essere significativamente differente dal valore Ti atteso.
5 - Per decidere se queste somme (Ti osservati) sono significativamente differenti dell’atteso, si calcola la statistica Fr Fr =
che (come nella formula) è la sommatoria dei quadrati degli scarti tra i k totali osservati e i corrispondenti attesi. E’ ovvio che tale valore di Fr tenderà - a 0 nel caso di accordo tra totali osservati e totali attesi (H0 vera), - a un valore alto al crescere dello scarto tra essi (H0 falsa).
Con i dati dell’esempio, si ottiene un valore di Fr Fr = (9 – 8)2 + (11 – 8)2 + (4 – 8)2 = 12 + 32 + 42 = 1 + 9 + 16 = 26 uguale a 26.
Nel caso di piccoli campioni (numero totale di dati N < 30-35 osservazioni che possono essere determinati, tra le situazioni più ricorrenti, da k = 3 e N £ 15 oppure da k = 4 e N £ 9) la significatività della statistica Fr è fornita da tabelle specifiche (riportate nella pagina seguente).
Per k = 3 e N = 4, i valori critici sono - 24 alla probabilità a = 0.10 - 26 alla probabilità a = 0.05 - 32 alla probabilità a = 0.01 Poiché il valore calcolato è stato 26, che coincide con la probabilità a = 0.05, si può rifiutare l’ipotesi nulla.
VALORI CRITICI DI Fr DEL TEST DI FRIEDMAN PER L’ANALISI DELLA VARIANZA NON PARAMETRICA A DUE CRITERI IN PICCOLI CAMPIONI
Per campioni di dimensioni medie (k tra 3 e 5 con N tra 5 e 10 in modo che k×N sua tra 25 e 40) è proposto l’uso della distribuzione F di Fisher, con gdl uguali a k-1 e (k-1)×(N-1). Si ricava il valore Fr attraverso
dove - Ti = Somma dei ranghi per colonna - N = Numero di righe e k = numero di colonne o gruppi Si rifiuta l’ipotesi nulla quando - il valore di Fr calcolato è maggiore del valore critico di F di Fisher - con gdl (k-1) e (k-1)×(N-1).
ESEMPIO. Durante una settimana, in 5 zone di una città sono state calcolate le quantità medie delle polveri Pm 10, ottenendo la seguente serie di dati
Verificare se esiste una differenza significativa nella presenza di polveri tra le 5 zone.
Risposta. La semplice lettura dei dati evidenzia, la presenza - di grande variabilità tra giorni e tra zone, - della non normalità della distribuzione, - dell’uso di valori medi, al posto delle singole osservazioni (potrebbero anche essere le mediane , il terzo quartile o un indice qualsiasi di concentrazione). Sono tutte condizioni che impongono il ricorso al test non parametrico di Friedman.
Quindi - si trasformano i dati in ranghi, entro la stessa riga, - e si calcolano i totali per colonna (Ti)
Da questa tabella di ranghi, per usare la formula
si devono prima ricavare -
-
- N = 7 e k = 5
Da essi si ottiene
un valore di Fr = 22,27 con df 4 e 24 (ricavati da (5 – 1) e da (5-1)×(7-1)). Poiché il valore critico di F con df 4 e 24 - alla probabilità a = 0.001 è uguale a 7,39 si rifiuta l’ipotesi nulla di uguaglianza delle mediane dei valori giornalieri riportati, con probabilità di commettere un errore di primo tipo P < 0.001.
Per campioni
di grandi dimensioni (k ³ 5 e N abbastanza
grande in modo che k×N > 40), è stato proposto
un indice c2F che si distribuisce
approssimativamente come il Può essere stimato mediante la formula
c2F = in cui - la seconda parte è data dagli scarti al quadrato tra somma osservata ed attesa, - mentre la prima dipende dall’errore standard, determinato numero di dati, trattandosi di ranghi.
Per semplificare i calcoli, sono state proposte formule abbreviate. Una che ricorre con frequenza nei testi di statistica è
dove: - N è il numero di righe od osservazioni in ogni campione (tutte con il medesimo numero di dati), - k è il numero di colonne o campioni a confronto, -
Ti è la somma dei ranghi della colonna
I risultati possono essere confrontati con i valori critici di seguito riportati, tratti dalla distribuzione chi quadrato con df k-1, o comunque presi direttamente da una distribuzione chi quadrato.
NEL CASO DI k DATI PER CASELLA, (ovviamente il campione diventa abbastanza grande e si può ricorrere alla distribuzione c2) come le misure raccolte - in k stazioni o situazioni (riportate nei trattamenti), - in N giorni o su N individui (riportati nei blocchi), - con r repliche, uguali per ogni stazione o individuo (riportate all’incrocio tra trattamenti e blocchi) e quindi con esperimenti bilanciati come nella tabella sottostante, per verificare la differenza nelle tendenze centrali d’inquinamento tra le k stazioni, con ipotesi nulla H0: me1 = me2 = ... = meK contro l’ipotesi alternativa H1: non tutte le k mediane sono uguali
si deve 1 - trasformare i dati in ranghi in modo indipendente per ogni blocco, considerando entro essi contemporaneamente i kr dati,
2 - calcolare i totali Ti di ogni colonna o trattamento degli Nr ranghi,
3 - stimare il
valore
4 - la cui significatività è data dalla distribuzione c2(k-1) .
Nel caso di un solo dato o replica per casella (quindi r = 1), la formula precedente coincide con
L’efficienza asintotica relativa del test Friedman, rispetto al test F di Fisher-Snedecor di cui è il corrispondente non parametrico, - quando la distribuzione dei dati è una Normale, ha un valore uguale a 0,95k/(k+1) = (3/p)×k(k+1); - quando la distribuzione dei dati è una Rettangolare, ha un valore uguale a 1k/(k+1); - quando la distribuzione è Esponenziale Doppia, ha un valore uguale a 1,5k×(k+1) = (3/2) ×k×(k+1). Quando la distribuzione dei dati è normale, il test non parametrico ha una potenza leggermente inferiore a quella dell’ANOVA, che è tanto più sensibile quanto maggiore è il numero di gruppi; ma quando ci si allontana dalla normalità mentre ha una potenza superiore. Resta il vantaggio, già ripetuto per i test non parametrici, che le conclusioni di questo test non sono confutabili come quelle del test F di Fisher, quando non sono rispettate le condizioni di normalità dei dati.
ESEMPIO 1 (PICCOLI CAMPIONI E 1 DATO PER CASELLA). In un depuratore sono stati posti 4 filtri (A, B, C, D) lungo il percorso di distribuzione dell’acqua; si vuole verificare se esiste differenza nella quantità di sostanze eliminate, pesata dopo una settimana di attività. La qualità dell’acqua e quindi la quantità del materiale trattenuto è molto variabile, derivando a volte da pozzi e altre da bacini di deposito:
Si vuole verificare se esistono differenze significative nella quantità di materiale in sospensione che viene trattenuto dai 4 filtri
Risposta. I dati raccolti sono estremamente variabili tra prove e non sono distribuiti in modo normale. Le quantità misurate (non importa il tipo di scala) sono quindi trasformate in ranghi entro ogni riga come nella tabella sottostante
Successivamente si calcolano i totali dei ranghi per colonna (Ti ). Applicando la formula per piccoli campioni
Fr =
in cui
si ottiene un valore di Fr
Fr = (18,5 - 12,5)2 + (12,5-12,5)2 + (7,5 - 12,5)2 + (11,5 - 12,5)2 = 36 + 0 + 25 + 1 = 62
uguale a 62.
Per k = 4 e N = 5 alla probabilità a = 0.05 il valore critico riportato nella tabella precedente è 65.
Poiché il valore calcolato è 62, la probabilità P è maggiore di quella critica, fissata a 0.05. Quindi non è possibile rifiutare l’ipotesi nulla: non è dimostrata una differenza significative tra le mediane della quantità di materiale trattenuto dai 4 filtri.
ESEMPIO
2 (grandi campioni E 1 DATO PER CASELLA). Prodotto dalle
combustioni contenenti zolfo, il biossido di zolfo
Un’esposizione continua alla concentrazione di 0,03-0,05 ppm determina un peggioramento delle condizioni dei pazienti bronchitici; una esposizione di solo 20 secondi alla concentrazione 0,3-1 ppm può portare all'alterazione dell'attività cerebrale; più di 6 ore di esposizione ad oltre 20 ppm possono causare la saturazione delle vie e dei tessuti polmonari, con eventuale paralisi e/o morte.
Durante il periodo invernale, con una rilevazione continua, per 15 giorni sono state misurate le medie giornaliere presso 6 aree sia industriali che residenziali di una città. Si vuole verificare se la tendenza centrale delle emissioni del periodo è significativamente diversa tra le 6 zone di monitoraggio.
Risposta. I dati raccolti formano un campione di grandi dimensioni e le misure riportate utilizzano una scala d'intervallo o di rapporto. Tuttavia, la distribuzione è fortemente asimmetrica, in alcuni gruppi: anche senza una misura oggettiva di valutazione delle simmetrie e di confronto della varianza, è possibile osservare che l’intervallo di variazione di alcuni gruppi è molto è differente. Nel caso del problema, soprattutto è l'uso di valori medi che vieta il ricorso all'ANOVA parametrica.
E’ vantaggioso ed appropriato utilizzare il test di Friedman. A tal fine, - si trasformano i dati in ranghi entro la stessa riga; - successivamente, si calcolano le somme per colonna, come nella tabella sottostante Ricordando che N = 15 e k = 6 , dai dati della
tabella successiva, in cui i valori sono stati trasformati in ranghi entro la
stessa riga, si stima il valore
che risulta uguale a 16,57.
Il valore critico
del - alla probabilità a = 0.05 è uguale a 11,07 - mentre alla probabilità a = 0.01 è uguale a 15,09 - e alla probabilità a = 0.001 è uguale a 20,52. Di conseguenza, con probabilità P < 0.01 di commettere un errore di I° tipo, si rifiuta l'ipotesi nulla e si accetta l'ipotesi alternativa: le mediane dei 6 gruppi a confronto non sono tra loro tutte statisticamente uguali.
ESEMPIO 3 (CON k REPLICHE O MISURE RIPETUTE PER CASELLA). Per valutare la significatività delle differenze nei livelli d’inquinamento tra 4 stazioni collocate lungo un corso d’acqua, data la grande variabilità stagionale nelle portate d’acqua, i campioni sono stati raccolti alle stesse date, effettuando 2 prelievi in 5 giorni diversi
Esistono differenze significative nei livelli d’inquinamento delle 4 zone o stazioni? Risposta.
Dopo - aver trasformato i valori nei ranghi relativi entro lo stesso blocco, con una impostazione grafica leggermente diversa da quella della tabella precedente, per meglio evidenziare che si tratta di repliche nelle stessa stazione e alla stessa data, - e aver calcolato i totali dei ranghi per colonna, il cui totale STi (23 + 32 + 56 + 69) = 180 è uguale a 180 e che, come verifica di non aver commesso errori nella trasformazione in ranghi e nelle somme successive, deve essere uguale a
STi = (con i dati dell’esempio STi = è infatti uguale a 180)
- con la formula generale
dai dati dell’esempio, dopo aver stimato che il totale atteso di ogni colonna è uguale a 45
- si calcola il
valore di
=
che risulta uguale a 1,875 con 3 gdl. Poiché alla probabilità a = 0.05 il valore critico del chi quadrato con 3 gdl è uguale a 7,815 non è possibile rifiutare l’ipotesi nulla.
Correzione per valori identici o ranghi ripetuti (ties). Con dati discreti e
scale semiquantitative od ordinali, i valori identici possono essere numerosi.
La varianza della distribuzione campionaria diventa minore; si rende necessario
apportare una correzione al valore di Si ottiene il valore
corretto di
dove: - N è il numero di righe o osservazioni per gruppo, - k è il numero di colonne o gruppi, - p è il numero di dati con lo stesso valore, e quindi con lo stesso rango, nella medesima riga; - rij è la dimensione dei ranghi ripetuti.
Nel calcolo della correzione,
con rij = 1 vengono inclusi anche i dati con valori che
compaiono una sola volta nella stessa riga. Pertanto essi contribuiscono per un
valore -
i
valori che compaiono 2 volte contribuiscono per un valore -
quelli
che compaiono 3 volte per un valore
ESEMPIO 4 (CON CORREZIONE PER TIES). Al fine di ottenere un quadro possibilmente completo della qualità dell'aria, in 6 zone di una città (centro storico (A), 3 aree periferiche (B, C, D) e 2 zone industriali (E, F)) sono state collocate stazioni di rilevamento per misurare con continuità tutti i parametri indicati dalla legge. Sono stati misurati gli inquinanti: anidride solforosa, ossidi di azoto, ossido di carbonio, fluoro, piombo, polveri, ozono, idrocarburi. Per ognuno di essi è stato valutato il grado di rispetto delle norme di legge. Inoltre sono stati rilevati alcuni parametri meteorologici che influiscono sulla qualità dell'aria: velocità e direzione del vento, temperatura, umidità, irraggiamento solare. Per una più facile e diffusa comprensione della situazione da parte della popolazione e degli amministratori, i tecnici hanno divulgato i dati con cadenza settimanale ed hanno elaborato un criterio che definisce il "giudizio sintetico" di qualità dell'aria in 5 classi: buona (++), discreta (+), mediocre (=), scadente (-), pessima (--).
I dati riportati in tabella sono i risultati di 10 settimane.
Si vuole verificare se tra le 6 zone esiste una differenza significativa nei giudizi mediani della qualità dell’aria.
Risposta. L'analisi statistica richiede preliminarmente la trasformazione dei giudizi sintetici in una scala di rango. E’ un campione di grandi dimensioni, con misure ordinali o semiquantitative. Un modo razionale di trasformazione dei simboli in ranghi potrebbe essere l’assegnazione del valore 1 alla zona che ha la migliore qualità dell'aria e progressivamente un valore maggiore al crescere dell'inquinamento, fino ad assegnare 6 alla zona la cui qualità dell'aria è stata giudicata la peggiore. Nulla cambia per l'analisi statistica se si agisse nel modo opposto, assegnando valori da 6 a 1. Nel caso di valutazioni identiche entro la stessa riga, si deve assegnare lo stesso valore stimato come media aritmetica dei ranghi occupati.
Per facilitare il
calcolo della correzione per misure ripetute i ties, è utile
riportare anche la somma dei valori
La somma dei valori
per i ranghi ripetuti (
Nella formula generale c2F =
al denominatore al posto di Nk(k+1) si sostituisce la formula con i ties
dove: - N è il numero di righe o osservazioni per gruppo, - k è il numero di colonne o gruppi, - p è il numero di dati con lo stesso valore, e quindi con lo stesso rango, nella medesima riga, - rij è la dimensione dei ranghi ripetuti.
Con i dati
dell’esempio, il valore
e svolgendo i calcoli
si ottiene
un risultato uguale a 26,96. Il valore di
Questo ultimo esempio dimostra come l’applicazione di questo test possa essere esteso, nel pieno rispetto della sua validità, a indici complessi determinati dalla somma o dalla media di una serie di parametri. A maggior ragione, questo test può essere esteso a indici sintetici semplici come medie e mediane oppure quantili specifici, come possono essere il primo e il terzo quartile. Ovviamente è richiesta una serie almeno una decina distribuzioni, raggruppate in k classi.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||