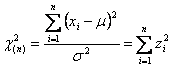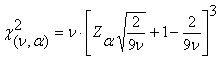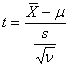|
DISTRIBUZIONI e leggi di probabilità'
2.5. DISTRIBUZIONI CAMPIONARIE DERIVATE DALLA NORMALE ED UTILI PER L’INFERENZA
La distribuzione normale è valida per campioni molto numerosi, teoricamente infiniti. Spesso è possibile disporne nella statistica economica e sociale, in cui si analizzano i dati personali di una regione o una nazione. Nella pratica della ricerca statistica biologica, naturalistica ed ambientale, per l’inferenza sono disponibili alcune decine, al massimo poche centinaia di osservazioni. In molti settori della ricerca applicata, molto spesso i campioni hanno dimensioni ancora minori e la loro numerosità gioca un ruolo importante, nel determinare la forma della distribuzione. Essa non può più essere considerata normale od approssimativamente tale, ma se ne discosta quanto più il campione è piccolo. Per l’inferenza, nella statistica parametrica l’ipotesi fondamentale è che questi campioni siano estratti da una popolazione normalmente distribuita. E’ un’ipotesi limitativa, ma basilare per le distribuzioni t di Student e F di Fisher, che insieme rappresentano le distribuzioni fondamentali dell’inferenza statistica parametrica. E’ importante comprendere come le 3 distribuzioni più utilizzate nell’inferenza statistica, la distribuzione c2 di Pearson in quella non parametrica, la distribuzione t di Student e la F di Fisher, per la statistica parametrica, siano legate logicamente e matematicamente con la distribuzione normale e tra loro.
2.5.1 LA DISTRIBUZIONE c2
La distribuzione Chi-quadrato ( c2 ), il cui uso è stato introdotto dallo statistico inglese Karl Pearson (1857–1936), può essere fatta derivare dalla distribuzione normale. Date n variabili casuali indipendenti x1, x2, …, xn, normalmente distribuite con m = 0 e s = 1, il c2 è una variabile casuale data dalla somma dei loro quadrati.
La funzione di densità di probabilità della distribuzione c2 è f(x) = K × x (n / 2) - 1 exp (-x/2) dove n = 1, 2, ... e K = 2 - n / 2 / G ( n / 2 ). La funzione di densità del c2 è determinata solo dal parametro n, il numero di gradi di libertà, pertanto viene scritta come c2(n).
La distribuzione c2 parte da n uguale a 1 e al suo aumentare assume forme sempre diverse, fino ad una forma approssimativamente normale per n = 30
Una buona approssimazione è data dalla relazione
Con n molto grande (oltre 200, per alcuni autori di testi) è possibile dimostrare che si ottiene una nuova variabile casuale (Z), normalmente distribuita, con media m uguale a 0 e deviazione standard s uguale a 1 La distribuzione chi quadrato e le sue relazioni con la normale possono essere spiegate in modo semplice attraverso alcuni passaggi. Supponendo di avere una popolazione di valori X, distribuita in modo normale,
la media m di questa distribuzione è E(X) = m e la varianza s2 è E(X - m)2 = s2
Se da questa distribuzione si estrae un valore X alla volta, per ogni singolo valore estratto si può stimare un punteggio Z2 standardizzato attraverso la relazione
Questo valore al quadrato, a differenza della Z, - può essere solo positivo e variare da 0 all’infinito,
Esso coincide con il chi quadrato con un grado di libertà.
Nella distribuzione Z, il 68% dei valori è compreso nell’intervallo tra –1 e +1; di conseguenza il chi quadrato con 1 gdl calcolato con
ha una quantità equivalente di valori (il 68% appunto) tra 0 e 1.
Analizzando non un caso solo ma due casi, con la formula
si calcola un chi quadrato con 2 gradi di libertà
fondato su due osservazioni indipendenti, che avrà una forma meno asimmetrica del caso precedente e una quantità minore di valori compresi tra 0 e 1.
Con n osservazioni Xi indipendenti, estratte casualmente da una popolazione normale con media m e varianza s2, si stima una variabile casuale chi quadrato
con n gradi di libertà e uguale alla somma degli n valori Z2.
Figura 25. Alcune distribuzioni c2(n), con gdl che variano da 1 a 10
La variabile casuale c2 gode della proprietà additiva: se due o più chi-quadrato, ognuno con i propri gdl sono indipendenti, dalla loro somma si ottiene un nuovo chi-quadrato con gdl uguale alla somma dei gdl.
Anche
la varianza campionaria s2 ha una distribuzione chi quadrato,
come verrà in seguito approfondito. Il c2 può servire per
valutare se la varianza H0: con ipotesi alternativa H1 H1 =
Per decidere alla probabilità a tra le due ipotesi, si stima un valore del chi quadrato
determinato
dal rapporto tra il prodotto degli n-1 gradi di libertà con il valore
sperimentale s2 e la varianza Per ogni grado di libertà, si dovrebbe avere una tabella dei valori del c2(n), come già visto per la distribuzione normale. Per evitare di stampare tante pagine quante sono i gradi di libertà, di norma viene utilizzata una tavola sinottica, una pagina riassuntiva, che per ogni grado di libertà riporta solo i valori critici più importanti corrispondenti alla probabilità a del 5% (0.05), 1% (0.01), 5 per mille (0.005) e 1 per mille (0.001).
All’uso del c2(n) è dedicato il successivo capitolo 3.
Non disponendo delle tabelle relative al chi quadrato e alla distribuzione normale, è possibile passare dall’una altra. Per passare dai valori del c2 al valore z, ricordando che, con n grande, la distribuzione c2(n) è approssimativamente normale, è possibile ricorrere alla relazione
za =
poiché quando i gradi di libertà sono molto più di 100 la media m della distribuzione c2(n) è uguale a n e e la varianza s2 è uguale a 2n.
Per esempio, si abbia con n =100, alla probabilità a = 0.05 il valore di c2= 124,342; mediante la relazione
si ottiene un valore di z uguale a 1,72 mentre il valore corretto è 1,6449. L’errore relativo è del 4,5%.
Inversamente, dal valore di Z è possibile ricavare quello del c2(n) alla stessa probabilità a. Quando n è grande, maggiore di 100, per stimare il valore del chi quadrato che esclude una quota a di valori in una coda della distribuzione si ricorre alla relazione
in cui Za è il valore di Z alla probabilità a prefissata.
Per esempio, con n =100, alla probabilità a = 0.05 con il valore di Z = 1,6449 mediante la relazione
si
calcola un valore di
Una approssimazione ancora migliore, che fornisce una stima accurata anche con pochi gradi di libertà (n), è stata proposta da Wilson e Hilferty nel 1931 con la relazione
Per esempio, con n =10, alla probabilità a = 0.05 con il valore di Z = 1,6449 mediante la prima relazione, valida per n grande
si trova
un valore di mentre con la seconda relazione
si
trova un valore di Nelle 2 tabelle successive, sono riporti i valori di z alle varie probabilità a per trovare il valore corrispondente del c2 per i gradi di libertà n prefissati (la tabella del chi quadrato è riportata alla fine del terzo capitolo).
Occorre ricordare che anche la distribuzione chi quadrato è normale, quando n è molto grande. Ciò spiega, in modo semplice ed intuitivo, perché in tale situazione quando Z è uguale a 0, alla probabilità a corrispondente al 50%, si abbia un valore del chi quadrato uguale alla sua media n. La tabella dei valori critici mostra che con gradi di libertà n = 100, la media (corrispondente alla probabilità a = 0.500) non è esattamente 100 ma 99,3341 a dimostrazione del fatto che non è una distribuzione perfettamente normale.
2.5.2 LA DISTRIBUZIONE t DI STUDENT
La distribuzione t di Student (pseudonimo del chimico inglese Gosset che ne propose l’applicazione al confronto tra medie campionarie) considera le relazioni tra media e varianza, in campioni di piccole dimensioni, quando si utilizza la varianza del campione. La scelta tra l’uso della normale o della distribuzione t di Student nel confronto tra medie deriva appunto dalla conoscenza della varianza s2 della popolazione o dal fatto che essa sia ignota e pertanto che, in sua vece, si debba utilizzare la varianza campionaria s2. Se una
serie di medie campionarie ( t2 = dove i gdl n corrispondono a N –1, con N uguale al numero totale di dati.
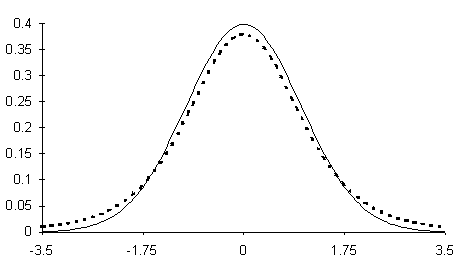
La curva corrispondente è simmetrica, leggermente più bassa della normale e con frequenze
maggiori agli estremi, quando il numero di gdl (n) è molto piccolo.
Per n che tende all’infinito, la curva tende alla normale.
Figura 26. Confronto tra la densità di probabilità della v.c. t di Student con gdl 5 (linea tratteggiata) e la distribuzione normale corrispondente, con stessa media e stessa varianza (linea continua).
2.5.3 LA DISTRIBUZIONE F DI FISHER
Un’altra distribuzione di notevole interesse pratico, sulla quale è fondata l’inferenza di molta parte della statistica parametrica, è la distribuzione F. Essa corrisponde alla distribuzione del - rapporto
di 2 variabili casuali chi-quadrato indipendenti (A e B), divise per i
rispettivi gradi di libertà (indicata da
F = (A/m) / (B/n)
Questo rapporto F è definito tra 0 e + ¥. La curva dipende sia dal valore di n1 e n2, tenendo conto delle probabilità a. Di conseguenza, in quanto definita da tre parametri, la distribuzione dei valori di F ha tre dimensioni. Il problema della rappresentazione dei valori di F è risolto praticamente con 2-4 pagine sinottiche, che riportano solo i valori più utilizzati, quelli che fanno riferimento in particolare alle probabilità 0.05, 0.01 e, più raramente, 0.005 e 0.001.
L’ordine con il quale sono riportati i due numeri che indicano i gradi di libertà è importante: la densità della distribuzione F non è simmetrica rispetto ad essi. Per convenzione, le tavole sono calcolate per avere F uguale o maggiore di 1. Per primo si riporta sempre il numero di gradi di libertà del numeratore, che è sempre la varianza maggiore, e per secondo quello del denominatore, che è sempre la varianza minore. Il valore di F in teoria può quindi variare da 1 a +¥. In realtà sono molto rari i casi in cui supera 10; avviene solo quando i gradi di libertà sono pochi.
Storicamente, - la distribuzione F è stata proposta dopo la distribuzione t e ne rappresenta una generalizzazione. Tra esse esistono rapporti precisi: - il quadrato di una variabile casuale t di Student con n gradi di libertà è uguale ad una distribuzione F di Fisher con gradi di libertà 1 e n.
t2(n) = F(1,n) oppure t(n) =
E' una relazione che sarà richiamata diverse volte nel corso, in particolare quando si tratterà di passare dal confronto tra più medie al confronto tra solo due. Inoltre il test t di Student permette confronti unilaterali più semplici ed immediati, che in molti casi sono vantaggiosi rispetto a quelli bilaterali. Anche questi concett saranno sviluppati nella presentazione dei test d'inferenza. Aree in una coda della curva normale standardizzata
La tabella riporta la probabilità nell’area annerita
Valori della distribuzione normale standardizzata.
La parte annerita rappresenta l’area sottostante la distribuzione normale standardizzata dalla media aritmetica a z.
Valori dell’integrale di probabilità della distribuzione normale standardizzata
L’area annerita rappresenta la probabilità di ottenere un valore dello scarto standardizzato minore di z.
Area nelle due code della distribuzione normale standardizzata
La tabella riporta le probabilità nelle aree annerite.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |