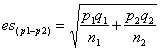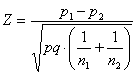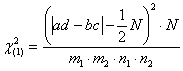|
COEFFICIENTI DI ASSOCIAZIONE, DI COGRADUAZIONE E DELL’ACCORDO RISCHIO RELATIVO E ODDS RATIO
20.1. I PRIMI ANNI DEL CHI- QUADRATO: CENNI SU NASCITA ED EVOLUZIONE
Le misure di
associazione sono fondate sul valore del - un valore di
associazione è significativo, se lo è il E’ quindi
fondamentale una conoscenza approfondita delle sue origini e delle sue
caratteristiche distintive del
Per questa rilettura storica e di approfondimento dei metodi già presentati nei capitoli iniziali, sono di aiuto due pubblicazioni scientifiche internazionali: 1 - l’articolo di
Frank Yates (1902-1994, già assistente di Fisher nel 1931 presso
l’Istituto di ricerche agrarie Rothamsted di Londra) del 1984 intitolato Test
of Significance for 2 x 2 Contingency Tables (su Journal of the
Royal Statistical Society, A, Vol. 147, Part.3, pp.: 426-463), nel quale
sono presentate le idee originarie su cui è stato impostato il test di
significatività per tabelle di contingenza 2 x 2; questo articolo è stato
pubblicato a 50 anni esatti di distanza dal suo articolo del 1934, il famoso Contingency
tables involving small numbers and the - la rassegna sull’evoluzione di questi metodi scritta da Noel Cressie e Timothy R. C. Read nel 1989 Pearson’s X2 and the Loglikelihood Ratio Statistic G2: A Comparative Review (pubblicata su International Statistical Review Vol. 57, 1, pp.: 19-43).
Nel paragrafo che
intitola Early History, F. Yates inizia la sua rassegna
dell’evoluzione dei concetti dalla proposta originaria formulata da Karl Pearson
(1857-1936) nel 1900, per applicare test sulla bontà dell’adattamento (test
for goodness of fit). La nascita del
Questo test è proposto per - confrontare un gruppo di frequenze osservate in un esperimento con un gruppo di frequenze attese, che sono stimate sulla base di un modello indipendente dai dati raccolti.
Le frequenze possono essere - sia il risultato del raggruppamento di dati continui in categorie, - sia il conteggio di dati originariamente qualitativi, come avviene nelle tabelle di contingenza.
E’ l’utilizzazione
più semplice di è fondato sulla relazione
dove - X = - - e dove p =
Sempre nell’articolo di Karl Pearson del 1900, - la
distribuzione asintotica di X2 è fornita dal Questa
corrispondenza asintotica tra - le frequenze attese siano infinite in tutte le celle.
E’ una assunzione teorica, soddisfatta in pratica quando - ogni frequenza
attesa ( poiché la formula
del X2 è derivata da una distribuzione poissoniana, in cui la
probabilità
Karl Pearson
affermò anche che, quando le probabilità - per un test
d’inferenza è ancora adeguato il Tale affermazione, seguita per circa vent’anni, sollevò un’ampia discussione. La soluzione
corretta è stata proposta solamente nel 1924 da Ronald Aylmer Fisher
(1890-1962) con l’articolo The conditions under which In una tabella r x c, le frequenze attese sono ricavate dai totali delle frequenze osservate. Pertanto - i gradi di
libertà sono
In una tabella di
contingenza 2 x 2 (ricordando che per convenzione con la simbologia classica
i gradi di libertà
sono Infatti, in questo metodo condizionale proposto da Fisher, - i totali - che rappresenta l’unico dato atteso che è effettivamente libero di assumere qualsiasi valore.
La generalizzazione
di questo concetto porta al fatto che in una tabella - i gradi di
libertà sono - non L’errore di Pearson diventava particolarmente grave in una tabella 2 x 2, poiché - il
Nel 1911, pochi anni dopo l’articolo di Pearson del 1900, George Udny Yule (1871-1951) propone un test per l’associazione in tabelle di contigenza 2 x 2, con il volume Introduction to the Theory of Statistics (London, Griffin). In campioni grandi, si può utilizzare - la
stima dell’errore standard, che per una proporzione è
Per una differenza
campionaria o osservata dove l’errore standard diventa
Se tra le frequenze
relative Con questa stima combinata, come dimostrato nel capitolo sul chi-quadrato, il risultato del test di Yule
- è equivalente al
test In realtà, nel suo
testo Yule non fa menzione di questa corrispondenza. Presumibilmente
perché al test
Per il calcolo è
Sulla base di
concetti uguali e metodi analoghi a quelli che porteranno alcuni decenni dopo
alle tecniche Monte Carlo e a quelle di ricampionamento, allo scopo di
effettuare una verifica empirica dei modelli matematici della distribuzione I risultati empirici coincidono con quelli del modello, ma con una stima diversa da quella proposta da Pearson per i gradi di libertà. Tuttavia Greenwood e Yule non pubblicarono questi risultati. E’ R. A. Fisher
che nel 1922, con l’articolo On the interpretation of Ora, da decenni, è universalmente accettata la correttezza dell’impostazione di Fisher.
Mentre con campioni grandi la proposta di Udry di approssimazione alla normale è universalmente accettata, con campioni piccoli il problema è più complesso e controverso. Il metodo più diffuso
è dovuto a R. A. Fisher, proposto nel suo testo del 1925 Statistical
Methods for Research Workers. E’ un metodo esatto, che fornisce
direttamente la probabilità della risposta sperimentale e di ogni altra
risposta possibile. E’ fondato sul fatto che i totali marginali sono inclusi
nella valutazione delle probabilità: si tratta di una restrizione (definita in
termini tecnici ipotesi condizionale) che è implicita nel calcolo del Nel 1934 Yates
dimostra che la distribuzione del valore del In tabelle 2 x 2, la formula abbreviata più conveniente diventa
Fornisce un risultato del tutto corrispondente al sottrarre 0,5 alla differenza tra osservato e atteso in ogni casella.
Mentre il metodo esatto è un test essenzialmente a una coda, in quanto permette di stimare la probabilità del singolo evento e di sommarlo poi con tutti gli eventi più estremi nella stessa direzione, il Lo stesso concetto è valido per la posto di Udry sul confronto tra due proporzioni con la distribuzione Z, che può essere sia unilaterale che bilaterale.
Nell’articolo del 1984, tra le altre Yates fornisce due risposte interessanti in merito alle controversie sul chi quadrato. Le critiche riguardavano in particolare due aspetti 1 - l’uso dell’approccio
condizionale in tabelle 2 x 2, poiché secondo alcuni statistici è logico
nella stima delle frequenze attese mantenere costante le dimensioni dei due
campioni, ma è poco convincente mantenere costante anche la proporzione 2 - le probabilità
Yates risponde: 1 - L’uso dei totali marginali
ricavati dalla distribuzione osservata per calcolare i valori attesi è una restrizione
che di fatto è implicita già nel test 2 - L’uso di livelli nominali convenzionali di significatività come il 5 e 1 per cento, quando i dati sono discontinui, deve essere attuato con buon senso. Il simbolismo matematico adottato dalla scuola di Neyman-Pearson
o quello ancora
più assurdo, se
ha incoraggiato l’uso di livelli nominali che può essere gravemente fuorviante con dati discreti. With discontinous data, the use of nominal levels can be seriously misleading (p. 435, terza riga dal fondo). Esemplifica questo concetto evidenziando che se si lancia una moneta 10 volte, - la probabilità di trovare 9 volte oppure 10 volte testa ha una probabilità di 1,1 per cento, - la probabilità di trovare 8 o più volte testa ha una probabilità del 5,5 per cento. Non esiste alcun motivo per confrontare tali probabilità con quelle riportate su una scala continua di 1,0 e 5,0 per cento. E’ più corretto ragionare e decidere sulla base di queste probabilità che sono state ricavate: The actual significance probability attained should therefore always be given when reporting on discontinous data (pag. 437, seconda riga).
E’ di particolare
importanza questa seconda osservazione, che è estensibile a tutta la statistica
non parametrica nel caso di piccoli campioni. Inoltre assume una rilevanza
generale, per l’interpretazione da fornire quando la probabilità - superare o meno il valore critico prefissato per quantità minime non è un fattore distintivo rilevante, per la significatività del risultato.
| |||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |