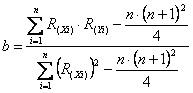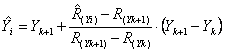|
TEST NON PARAMETRICI PER CORRELAZIONE, CONCORDANZA, REGRESSIONE MONOTONICA E REGRESSIONE LINEARE
21.16. LA REGRESSIONE MONOTONICA DI IMAN-CONOVER
In una distribuzione bivariata, nella quale - una variabile è identificata con la causa e è detta variabile indipendente, indicata con X, - l’altra è identificata con l’effetto e è detta variabile dipendente, indicata con Y, può sorgere il problema di verificare se al crescere della prima variabile la seconda cresce o diminuisce, senza richiedere che il rapporto sia di tipo lineare, cioè costante. E’ la regressione monotonica.
Tra i metodi presenti in letteratura, quello proposto da R. L. Iman e W. J. Conover nel 1979 (vedi The use of the rank transform in regression su pubblicato su Technometrics vol. 21 pp. 499-509) è il più diffuso; inoltre, è presentato nel testo di Conover del 1999 (Practical Nonparametric Statistics, 3rd ed. John Wiley & Sons, New York, 584 p.), indubbiamnete da annoverare tra quelli internazionali più noti.
Da esso è tratto l’esempio seguente, qui illustrato con una presentazione più dettagliata della metodologia, una esposizione di tutti i passaggi logici e con la correzione di alcuni risultati.
La teoria sottostante a tale approccio, già presentato nel paragrafo dedicato alla correlazione non parametrica, è che - quando tra i ranghi di due variabili esiste regressione lineare, - tra i loro valori osservati (su scale ad intervalli o di rapporti) esiste regressione monotonica. Di conseguenza, è utile calcolare la retta di regressione lineare sui ranghi e la sua significatività. Per questo ultimo test, cioè per valutare l’ipotesi nulla H0: b = 0 si ritorna alla correlazione non parametrica già illustrata, per un concetto del tutto analogo alla verifica della regressione lineare di Theil.
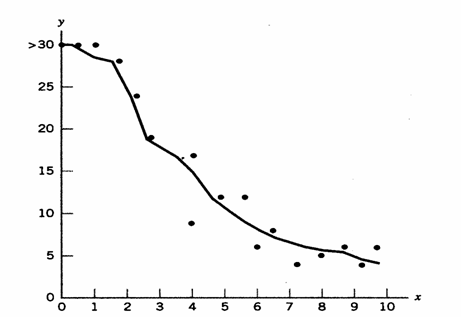
Per valutare se l’aggiunta di zucchero al mosto d’uva favorisce la fermentazione, in 17 esperimenti indipendenti alla stessa quantità di mosto è stata aggiunta una quantità differente di zucchero (X, misurata in libbre); successivamente per 30 giorni è stato valutato se la fermentazione era iniziata (Y, misurata in giorni trascorsi). Dopo 30 giorni l’esperimento è stato interrotto. Nei tre contenitori ai quali erano state aggiunte le quantità di zucchero minori (cioè X uguale a 0,0; 0,5; 1,0 libbre) la fermentazione non era ancora iniziata: a essi è stata attribuita la misura approssimata Y >30.
Curva di regressione monotonica con i dati osservati
I dati dei 17 campioni
indipendenti (individuati nella colonna 1 dalle lettere da A a S) sono
riportati nelle colonne 2 (
Il metodo di Iman-Conover richiede due serie di passaggi: - la prima per calcolare la retta di regressione sui ranghi dei valori; - la seconda per ritornare da questa retta ai valori originali, trasformadola in una serie di segmenti che descrivono la regrassione monotonica di Y su X, nella scala effettivamente utilizzata.
Questi passaggi logici e metodologici sono: 1 - Trasformare i valori della variabile X e Y (riportati nelle colonne 2 e 3 della tabella precedente) nei loro ranghi (come nelle colonne 4 e 5).
Il grafico sottostante, come evidenzia anche la differente scala riportata in ascissa e in ordinata, è la rappresentazione dei punti mediante i loro ranghi.
RETTA DI REGRESSIONE OTTENUTA CON LA TRASFORMAZIONE DEI DATI IN RANGHI
2 – Calcolare la
retta sui ranghi (quella rappresentata nella figura). Dapprima si stima il
coefficiente angolare
una formula corrispondente a quella abbreviata della retta parametrica. Utilizzando i dati dell’esempio, dove - - -
si ottiene il
coefficiente angolare Successivamente,
si stima l’intercetta
Utilizzando i dati dell’esempio
risulta Di conseguenza, la retta di regressione stimata mediante i ranghi è
3 – Questa formula
permette di calcolare i valori attesi per ogni rango di Y a partire dai
ranghi di X, cioè gli Ad esempio, - per il campione
A con
- per i campioni G
e H con
La retta è
costruita con i punti (
4 – Per valutare la significatità della retta così calcolata (H0: b = 0), quindi se esiste regressione monotonica sui dati originali, è sufficiente valutare la significatività della correlazione non parametrica (H0: r = 0); può essere ottenuta indifferentemente con il test r di Spearman oppure con il t di Kendall.
5 - Dalla retta
calcolata sui ranghi, si ritorna alla scala originale di X e Y
calcolando gli
6 - Per identificare
tutti i valori a)
se
b)
se
c)
se
d)
se
Ad esempio, -
per
il campione A il valore stimato del rango è -
per
il campione B il valore stimato del suo rango è
- per il campione C
- per il campione D
- per il campione E
- per il campione F
- per il campione G
I valori stimati sono riportati nella colonna 9 (gli altri sono ripresi da Conover). Nell’esempio utilizzato, tre valori sono molto approssimati (>30) e tra loro identici, quindi che introducono bias nei calcoli. Il metodo dimostra di essere abbastanza robusto da riuscire ugualmente a fornire stime della regressione monotonica. Tuttavia, lo stesso Conover raccomanda di usare scale continue, quindi definite con precisione e senza valori identici
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||