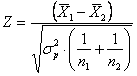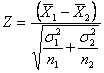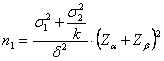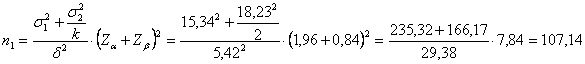VERIFICA DELLE IPOTESITEST PER UN CAMPIONE SULLA TENDENZA CENTRALE CON VARIANZA NOTAE TEST SULLA VARIANZA CON INTERVALLI DI CONFIDENZA
4.11. POTENZA E NUMERO DI DATI PER LA SIGNIFICATIVITA’ DELLA DIFFERENZA TRA DUE MEDIE, CON LA DISTRIBUZIONE NORMALE;
Per effettuate un test Z sulla significatività della differenza tra le medie di due campioni indipendenti, - quando le due varianze
- mentre quando le
due varianze si utilizza
In entrambi i casi, è possibile calcolare a priori il numero minimo - affinché la differenza attesa - risulti significativa alla probabilità a e con rischio b,
Nel primo caso, quando le due varianze - la stima di da
Nel secondo, quando le due varianze - la stima di da
ESEMPIO 1. (USO DELLA FORMULA CON VARIANZE DIFFERENTI, tratto con modifiche da Bernard Rosner, 2000, Fundamentals of Biostatistics, 5th ed. Duxbury, Thomson Learning, XIX + 992 p. a pag. 307). Uno studio pilota, per preparare un test bilaterale sulla differenza tra le medie di due campioni indipendenti, ha dato i seguenti risultati
Se le statistiche dei dati campionari raccolti sono assunti come
stime corrette dei parametri delle due popolazioni, quanti dati - in un esperimento nuovo e con un rischio b = 0,20 - un test bilaterale sulle due medie risulti significato alla probabilità a = 0.05?
Risposta. Con - -
che servono almeno
In altri testi, è presentata una soluzione differente, fondata sull’analisi statistica delle due varianze campionarie. Attualmente è il metodo più utilizzato; è presentato in modo dettagliato nel capitolo sul test t di Student. La metodologia può essere esposta nei suoi passaggi logici fondamentali: 1 – Si verifica se
le due varianze campionarie I metodi più noti sono tre: a) il test F, dato dal rapporto tra la varianza maggiore e quella minore; b) il test di Bartlett, fondata sulla distribuzione chi quadrato; c) il test di Levene, che utilizza gli scarti di ogni dato dalla sua media di gruppo. 2 - Se il test
prescelto con ipotesi nulla H0: 3 – Si ricava la varianza comune, utilizzando le due devianze e i rispettivi gradi di libertà, come
Applicata ai dati campionari dell’esempio è
4 – Usando questa ultima come varianza
reale da
si ottiene una stima di
E’ un valore maggiore del precedente In questa ultima formula, la varianza maggiore e quella del campione
maggiore hanno un peso più rilevante sulla varianza comune. E, in questo caso,
il campione di dimensioni maggiori ha pure varianza maggiore. Quando metodi
differenti forniscono risposte non coincidenti, è sempre consigliato fare la
scelta più prudenziale. Per le dimensioni del campione, significa scegliere il
numero
Nei test che
confrontano le medie di due o più gruppi, un concetto molto importante nella
distribuzione del numero di osservazioni totale Dalla formula
è facile dedurre che la quantità Z è massima quando la quantità
è minima. Situazione che si
realizza quando, per lo stesso
Ma è una condizione
che non sempre conviene rispettare quando nella scelta del numero Un costo morale differente tra due campioni si ha quando, ad esempio, per valutare l’effetto di un farmaco, - a un gruppo di ammalati si somministra il farmaco che si ritiene migliore, - all’altro gruppo di ammalati il farmaco vecchio, ritenuto meno efficace, se non addirittura il placebo. E’ evidente che somministrare un placebo a un ammalato, lasciandogli credere che sia il farmaco, allo scopo di avere misure certe di confronto e così favorire la scelta della cura migliore, ha costi morali elevati. Una cautela moralmente obbligata è - ridurre il numero al minimo il numero di persone alle quali somministrare il placebo, - ma effettuando un test ugualmente potente.
Sovente, i due gruppi hanno semplicemente costi economici diversi, per i quali è facile definire il loro rapporto. Ad esempio, può essere la raccolta di dati ambientali in un’area vicino a casa e altri in un’area distante, che richiede spese di trasporto maggiori e più tempo. Definito il rapporto tra i due diversi costi, indicato con k, si costruiscono due campioni non bilanciati. Il problema ha varie soluzioni. Un metodo, riportato in alcuni testi, consiste nel - fissare - calcolare con
- calcolare con
In modo più semplice, la scelta di
come quello degli ammalati ai quali somministrare il farmaco
ESEMPIO 2 (Tratto, con modifiche, da Bernard Rosner, Fundamentals of Biostatistics, 5th ed. Duxbury, Thomson Learning, 2000, XIX + 992 p. a pag. 308 e con gli stessi dati dell’esempio 1). Con
quanti dati - con - e un rischio b = 0,20 - alla probabilità a = 0.05 un test bilaterale sulle due medie risulti significativo?
Risposta. Con - - per il campione 1
si stima e per il campione 2, più rapidamente,
si ricava ovviamente entrambi arrotondati all’unità
superiore ( Con la formula utilizzata per il campione 1, se applicata al campione 2,
si sarebbe stimato ugualmente
Con qualsiasi sbilanciamento, come questo
provocato dal rapporto - con due campioni bilanciati
servirebbero in totale - con due campioni differenti
servirebbero in totale per due test che hanno stessa potenza. Infatti sono stati calcolati per valori identici di a e b. Se si tratta di costi economici, ad
esempio con un rapporto - il costo di ogni dato del campione 2 è di 10 euro, è semplice calcolare che - con due campioni bilanciati il costo complessivo sarebbe stato di 4560 euro (152 x 20 + 152 x 10) - con due campioni differenti il costo complessivo sarebbe stato di 4310 euro (108 x 20 + 215 x 10)
Altre volte, il
numero totale Conoscendo N, - la suddivisione ottimale nei due gruppi
dipende dalle due deviazioni standard - e conviene rendere maggiore il gruppo con la deviazione standard maggiore, secondo il rapporto
in modo da avere per quel gruppo un errore standard proporzionalmente minore. Ovviamente, se Quando - le due
varianze sono uguali ( - i due campioni
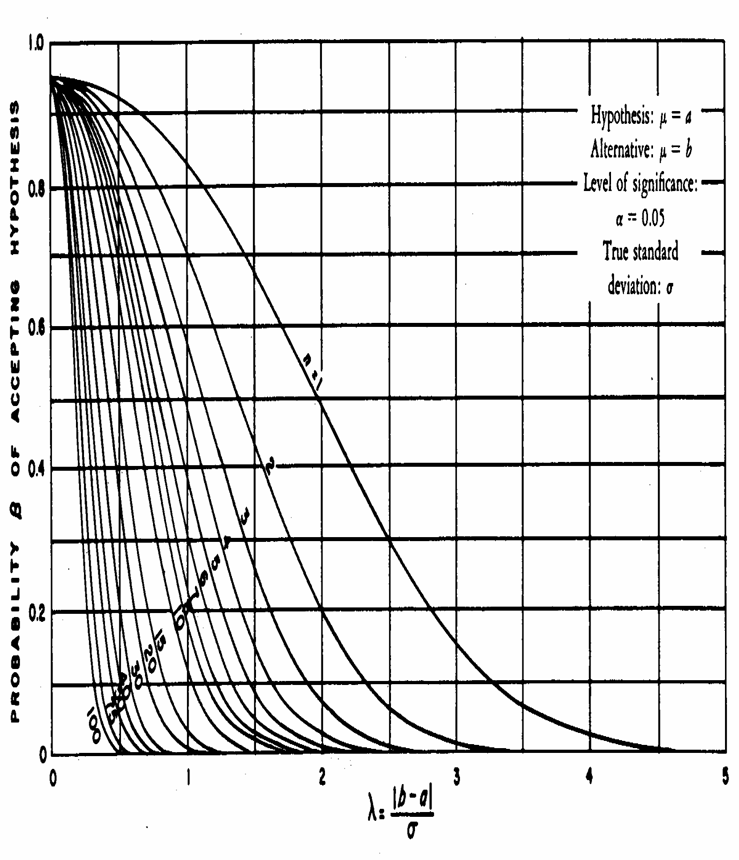
sono bilanciati ( è possibile ricorrere anche a metodi grafici, che forniscono risposte approssimate, quando il campione è grande a causa della difficoltà di leggere con precisione i grafici. La metodologia è del tutto analoga a quella già illustrata in precedenza per un campione, - ma con un calcolo differente del parametro l.
Con la figura riportata nella pagina precedente, (utile solamente per un test bilaterale, con a = 0.05) è possibile stimare a) il rischio b, b) la quantità dopo aver calcolato il parametro l attraverso la relazione
dove - - - - si sale verticalmente fino a incontrare
la curva - trasferito orizzontalmente sull’asse delle ordinate, esso indica il rischio b. B - Per stimare
le dimensioni minime ( - dopo aver individuato il valore di l sull’asse delle ascisse si sale verticalmente - e dopo aver prefissato il valore di b ci si sposta in modo orizzontale: - il punto di incrocio dei due segmenti
ortogonali individua la curva
Parte I - La quantità di
principio attivo immesso nel prodotto da due aziende farmaceutiche, misurato su
due campioni di 4 dati, è stato
Risposta. Usando la formula
si ricava
un valore Nella figura precedente, prendendo
sull’asse delle ascisse il valore - salendo verticalmente, si incontra la
curva per - che, trasferito orizzontalmente
sull’asse delle ordinate, indica In questo confronto, per trovare una
differenza significativa tra le medie di due campioni indipendenti, il test ha
un rischio
Parte II - Se si vuole che il test risulti
significativo ma con una potenza non inferiore all’80 per cento (quindi
Risposta. Sempre nella stessa figura, - si prende sull’asse delle ascisse il
valore - contemporaneamente sull’asse delle
ordinate si prende - queste due rette si incontrano in un
punto, che cade sulla curva Per ognuno dei due campioni servono almeno 10 dati.
Parte III - (CONFRONTO TRA IL RISULTATO DELLA FIGURA E DISTRIBUZIONE Z). Per una valutazione dei due metodi, è interessante confrontare il risultato ottenuto dal grafico con quello della distribuzione Z. Utilizzando
con
si ricava
la stima Coincide con la risposta precedente.
| |
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |