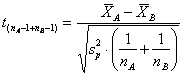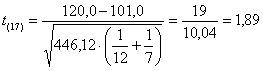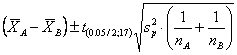|
METODI NON PARAMETRICI PER DUE CAMPIONI INDIPENDENTI
9.10. TEST S DI KENDALL E SUOI RAPPORTI CON IL TEST T E IL TEST U; POTENZA-EFFICIENZA DEI TRE TEST E CONFRONTI TRA I METODI.
Un altro test che affronta lo stesso problema, cioè il confronto tra le mediane di due campioni indipendenti, è il test S di Kendall. Fondamentalmente è una variazione del test U di Mann-Whitney, essendo fondato sulla stessa metodologia e esistendo una stretta corrispondenza tra i risultati. In mancanza dei valori critici di S, riportati in pochissimi manuali, con una trasformazione semplice è possibile utilizzare la tabella dei valori U. Tra i testi classici di statistica applicata che hanno una diffusione internazionale, questo test è riportato nel volume di Peter Armitage e Geoffry Berry del 1994 (Statistical Methods in Medical Research, edito da Blackwell Scientific Publication Limited, Oxford, tradotto in italiano nel 1996 con Statistica Medica. Metodi statistici per la ricerca in Medicina. McGraw-Hill, Libri Italia, Milano), dal quale sono tratti la presentazione, gli esempi e vari commenti.
Con un linguaggio molto sintetico, forse comprensibile solo a chi già conosce il test, questo volume presenta il test U di Mann-Whitney e il test sui ranghi di Wilcoxon; successivamente, in poche righe, espone il test S di Kendall, proposto appunto da M. G. Kendall nel suo volume del 1955 Rank Correlation Methods (2nd ed., Charles Griffin and Co., London). La presentazione di Armitage e Berry è utile soprattutto nella parte dove illustra le relazioni tra i metodi, poiché permette di passare con facilità dai risultati dell’uno a quelli dell’altro, come può essere richiesto nel confronto di pubblicazioni scientifiche appartenenti a scuole differenti. Allo scopo di approfondire i concetti già presentati nei paragrafi precedenti e in particolare per esercitare lo studente a un linguaggio diverso da quello utilizzato in questo corso, con termini più rispondenti ai canoni classici del linguaggio statistico avanzato anche se spesso poco comprensibili ai meno esperti, si riporta quasi integralmente la trattazione di questi argomenti fatta nel testo. Per approfondimenti ulteriori si rinvia ad esso, consigliato a chi vuole avere a disposizione i testi fondamentali della statistica applicata alle discipline biologiche, mediche e ambientali.
Supponiamo di avere
due gruppi di osservazioni: un campione casuale di
Nel test U di
Mann-Whitney, le osservazioni sono poste in ordine crescente di
grandezza. Vi sono UXY è il
numero di coppie per cui UYX è il
numero di coppie per cui Ogni coppia per la
quale Entrambe queste
statistiche possono essere utilizzate come base per un test, con risultati
esattamente equivalenti. Utilizzando UYX, per esempio, la statistica
deve essere compresa tra 0 e
Valori elevati
suggeriscono l’ipotesi di una differenza tra le popolazioni, con le
Nel test sui ranghi di Wilcoxon si presentano ancora una volta due statistiche equivalenti: T1 è la somma dei
ranghi delle T2 è la somma dei
ranghi delle Valori bassi assumono ranghi bassi (cioè rango 1 è assegnato al valore più piccolo). A ogni gruppo di osservazioni uguali è assegnato il rango medio del gruppo.
Il valore minimo
che la statistica T1 può assumere si ha quando tutte le T1 =
Il valore
massimo per T1 invece si ha quando tutte le In tal caso, T1 =
Il valore medio di T1, cioè il valore atteso sulla base dell’ipotesi nulla, è T1 =
Il test S di Kendall è fondato su una statistica che è definita in funzione delle due statistiche di Mann-Whitney: S = UXY - UYX Il valore minimo
(quando tutte le - Il valore
massimo (quando tutte le +
Il valore medio o valore atteso in base all’ipotesi nulla è 0 (la media tra questi due).
Le relazioni tra i test sono semplici e possono essere derivate dalle formule precedenti, dato che tutte si rifanno alle dimensioni dei due campioni indipendenti. Innanzitutto vi sono due relazioni tra le statistiche di Mann-Whitney (UXY e UYX) e tra le due statistiche di Wilcoxon (T1 e T2):
Esse dimostrano che i test basati sull’una o sull’altra statistica di ciascuna coppia sono equivalenti. Per esempio, dati T1 e le dimensioni dei due campioni , si può immediatamente calcolare T2 in base alla relazione appena riportata.
In secondo luogo, i tre test (T, U, S) sono collegati dalle seguenti formule:
I tre test sono esattamente equivalenti. La probabilità di osservare un valore T1 uguale o inferiore a quello osservato è esattamente uguale alla probabilità che un valore UXY sia maggiore o uguale a quello osservato. Pertanto, test di significatività basati su T1 o su UXY forniscono esattamente lo stesso livello di probabilità. La scelta tra questi due test dipende unicamente dalla familiarità con una certa forma di calcolo e dalla disponibilità delle tavole. Con valori ripetuti nelle osservazioni, le formule della varianza vanno modificate. Come per il test sui ranghi, le tavole dei valori critici sono da utilizzare con cautela in presenza di ripetizioni.
L’efficienza asintotica relativa del test T, del test U e del test S può essere valutata nei confronti del test t di Student per 2 campioni indipendenti, il test parametrico a loro equivalente. L’efficienza asintotica varia in funzione della distribuzione dei dati ed è uguale a quella già presentata per i test fondati sui ranghi nel caso di un campione e di 2 campioni dipendenti: - con una distribuzione normale dei dati è uguale a circa 0,95 (3/p), - con una distribuzione rettangolare dei dati è uguale a 1, - con una distribuzione esponenziale doppia è uguale a 1,50 (3/2).
Come già ricordato in varie situazioni e sarà sviluppato in particolare nei paragrafi dedicati alle trasformazioni dei dati, le variazioni misurate in percentuale presentano problemi non trascurabili nell’analisi statistica parametrica: - le varianze di proporzioni medie differenti sono differenti, per cui occorre la trasformazione angolare; - quando le quantità iniziali sono molto diverse, la informazione reale è quella di rango; - i cambiamenti possono essere in aumento, per cui si ottengono valori molto alti che determinano una distribuzione asimmetrica; - ma possono anche essere in diminuzione, fino alla scomparsa totale del fattore analizzato; di conseguenza, il valore diventa –100 e può essere ripetuto varie volte, determinando una distribuzione fortemente bimodale, non riconducibile alla normale con nessuna trasformazione.
ESEMPIO 1.(Impostato sull’analisi di variazioni percentuali) Illustriamo ora l’applicazione del test S di Kendall e dell’equivalente test U di Mann-Whitney ai seguenti due insiemi di dati:
X = Pazienti ospedalizzati, -100(12), -93, -92, -91(2), -90, -85, -83, -81, -80, -78, -46, -40, -34, 0, +29, +62, +75, +106, +147, +1321.
Y = Pazienti ambulatoriali, -100(5), -93, -89, -80, -78, -75, -74, -72, -71, -66, -59, -41, -30, -29, -26, -20, -15, +20, +25, +37, +55, +68, +73, +75, +145, +146, +220, +1044.
Queste misure rappresentano la variazione percentuale dell’area di ulcere gastriche dopo 3 mesi di trattamento, eseguendo il confronto tra 32 pazienti ospedalizzati e 32 pazienti ambulatoriali.
Nel calcolo di S, quando vi siano valori ripetuti, non è
necessario conteggiare 0,5 per ogni coppia (
In questo esempio si indichino con
Perciò P = 12(27) + 5(26) + 3(25) + 24 + 23 + 17 + 2(16) + 11 + 9 + 7 + 2(4) + 2 + 0 = 662 Q = 5(20) + 19 + 15 + 11 + 7(10) + 9 + 5(7) + 2(6) + 2(5) + 2(4) + 3 + 2(2) + 2(1) = 298 e S = 662 – 298 = 364 Da
dove
-
-
-
N
=
-
si ricava
e infine
Utilizzando l’approssimazione normale, lo scarto normale standardizzato è
Z =
Nella versione di Mann-Whitney, ogni ripetizione contribuisce per 0,5 a UXY e a UYX. Quindi per esempio UYX = 5(26) + 19,5 + 15 + 11,5 + … = 330
E(UYX) =
(Nel testo qui riportato, E(UYX) indica la media attesa di U nella condizione che H0 sia vera; nei paragrafi precedenti, questa media attesa è sempre stata indicata con mU) Inoltre
UYX –
E(UYX) = -182 (=
per cui
Z =
e quindi lo scarto standardizzato è Z = -2,47, come in precedenza, a parte il segno. E’ un esempio in cui la differenza tra i campioni di X e di Y non sarebbe stata rilevata da un test t. Le distribuzioni sono estremamente non – normali e il test t a due campioni dà t = 0,51 chiaramente non significativo.
Per la stima dell’intervallo di confidenza della differenza tra
le due tendenze centrali, supponiamo che le due distribuzioni abbiano
la stessa forma, ma differiscano di un d lungo la scala di misura, che risulta positivo
quando le
In primo luogo, si noti che UYX è il numero di coppie
in cui Sottraendo una quantità costante d da tutte le Calcolando nuovamente UYX dopo la sottrazione, si otterrebbe un test per l’ipotesi che lo spostamento, o la differenza mediana, sia di fatto d. I limiti di confidenza per lo spostamento d si ottengono, perciò, trovando quei valori che, sottratti da tutte le differenze, diano un risultato al limite della significatività. Ordinando le differenze, l’intervallo di confidenza è la parte di mezzo della distribuzione, con un numero di differenze escluse alle due estremità, in accordo con i valori critici del test UYX. Il numero di valori da escludere può essere valutato utilizzando la tabella dei valori critici di U, come illustrato nel seguente esempio. Una stima puntuale del parametro d è data dalla mediana delle differenze, poiché si tratta del valore che, sottratto da tutte le differenze, renderebbe la statistica del test uguale al suo valore atteso.
ESEMPIO 2. (Confronto tra test e intervallo di confidenza parametrico e non parametrico) Due gruppi di ratti femmine sono stati sottoposti a diete rispettivamente con alto (A) e basso (B) contenuto di proteine. Su ogni animale è stato calcolato l’aumento di peso il 28° e l’84° giorno di età. I risultati sono stati
Verificare la significatività della differenza tra le due diete e calcolarne l’intervallo confidenza con il test t e il test non parametrico corrispondente.
Risposta. Per verificare l’ipotesi nulla H0: mA = mB contro H1: mA ¹ mB con il test t di Student
si ottiene
un valore di t = 1,89 con 17 g.d.l., al quale corrisponde una probabilità P = 0.076 Secondo i due autori, “la differenza non è significativa al livello del 5% e dà solo un’indicazione vaga dell’effetto delle diete”.
I limiti di confidenza della differenza calcolati con la formula
mA – mB = applicata ai dati dell’esempio
risultano compresi tra –2,2 e 40,2.
Per verificare l’ipotesi H0: meA = meB contro H1: meA ¹ meB con un test non parametrico,
- è possibile utilizzare il test T di Wilcoxon
con Poiché la tavola dei valori critici del T di Wilcoxon in un test bilaterale alla probabilità a = 0.05 riporta T1 £ 46 la differenza tra le due mediane non risulta significativa.
Per calcolare l’intervallo di confidenza si utilizza distribuzione U, dove in un test bilaterale alla probabilità a = 0.05 è riportato il valore critico U £ 18. Dopo aver calcolato tutte le 84 (12 x 7) possibili differenze
per ottenere l’intervallo di confidenza al 95 % si eliminano le 18 più estreme in ogni coda. Nella distribuzione ordinata delle differenze, si ricava che - il limite inferiore è –3, - il limite superiore è 40, - mentre la mediana è 18,5 (cadendo tra 18, il 42° valore, e 19, il 43°).
Per campioni di dimensioni maggiori di quelli riportati nella tabella
dei valori critici, cioè con
U = Ad esempio,
-
per
a = 0.05 bilaterale
e con mentre con Z = 1,96 si stima
U = U = 127,54
-
per
a = 0.01 bilaterale e con mentre con Z = 2,576 si stima
U = U = 104,77.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |